前言
在研究rabbitmq使用特性时,发现如果在连接connection上一段时间内没有消息流动时,就会出现connection自动断开的现象,后台日志中有大量断连的错误日志,这个时候如果client开启了自动恢复连接的功能时,client会自动尝试重新连接服务器。而且client和broker之间是有heartbeat链路保活机制的,在链路空闲的情况下,默认60秒发送一次心跳。从而确保TCP连接不会由于长时间没有数据流动被防火墙,NAT路由等设备清除转发记录,导致TCP连接断连失效,所以从理论上来说,这种空闲连接自动断连的现象应该是不可能出现的,那么又是什么原因导致这一问题的出现呢?下面将逐步分析问题的原因及解决方法。
具体现象
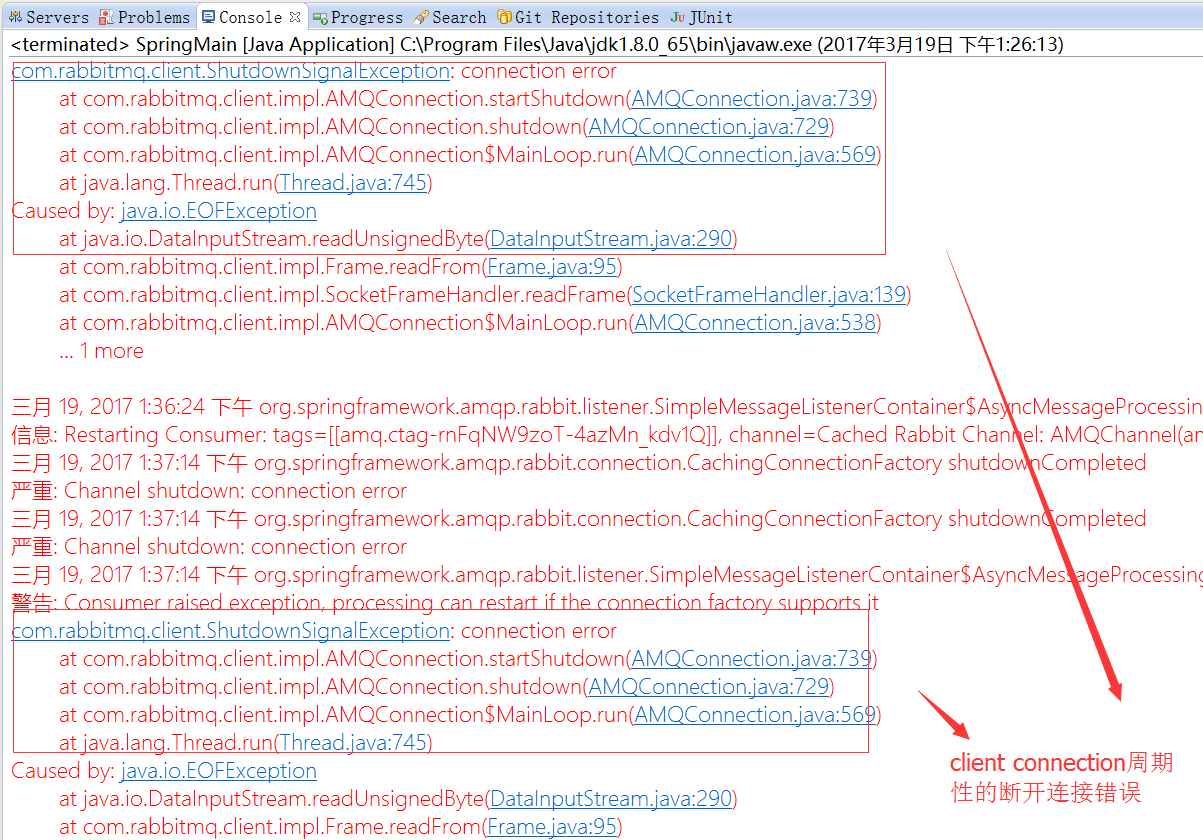
client连接经常性的断开连接,后台有大量断连的错误日志。
问题原因
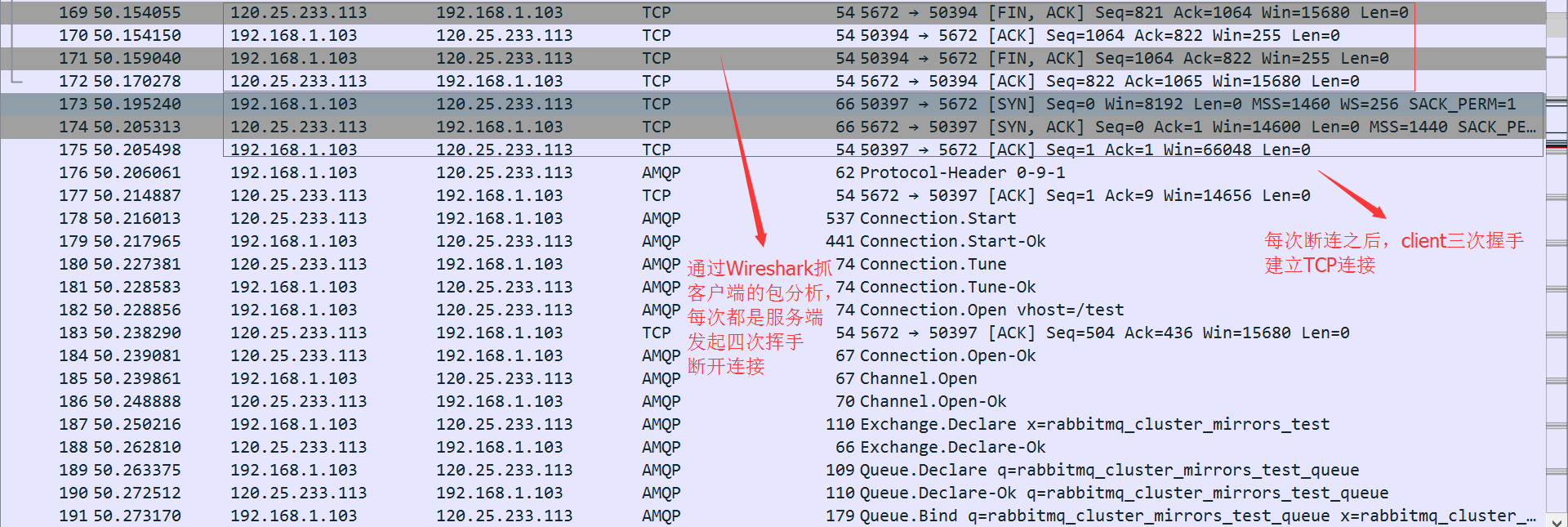
通过在client本机上安装Wireshark抓包分析工具,发现client与server之间有大量周期性的TCP四次挥手断连报文,而由于rabbitmq client开启了自动链接恢复的功能,每次断开连接之后,client又会主动发起三次握手建立TCP连接,然后重新发起amqp协议握手等操作,所以才会出现大量周期性的上图中的报文。
抓包过滤条件:ip.src eq 120.25.233.113 or ip.dst eq 120.25.233.113
从上述抓包中,我们可以得出每次都是由于服务端主动断开TCP连接,导致断连的问题,但是从理论上来说只要rabbitmq client和server协商好了心跳时间间隔,是不会出现断连的。这时联想到了我们现有的架构中,在client和rabbitmq server之间还有个haproxy做为高可用的代理机。那么很有可能是由于haroxy的原因导致的断连。
通过查看haproxy的配置haproxy.cfg发现了如下三个timeout配置:defaults
# haproxy与后端服务器连接超时时间,如果在同一个局域网可设置较小的时间
timeout connect 5000ms
# 定义client与haproxy非活动连接的超时时间
timeout client 50000ms
# 定义haproxy与后端服务器非活动连接的超时时间
timeout server 50000ms
listen rabbitmq-cluster
bind 0.0.0.0:5672
mode tcp
option tcplog
balance roundrobin
server rabbitmq-node1 10.116.84.117:5673 check inter 3000 rise 3 fall 3 weight 1
server rabbitmq-node2 10.116.84.117:5674 check inter 3000 rise 3 fall 3 weight 1 backup
由于timeout client和timeout server都是50000ms(即50秒),而rabbitmq client和server之间默认的TCP链路保活心跳间隔是60秒(大于haproxy中设置的timeout时间),所以才会周期性的出现TCP连接断开的问题。
解决方案
- 调整rabbitmq client和server协商的心跳间隔时间,默认是60秒;
- 调整haproxy timeout时间;
这里我们选用方案1,更灵活方便一些,直接在创建connection-factory时,调小心跳间隔的时间即可(这里指定心跳间隔40秒)!<rabbit:connection-factory id="connectionFactory" host="120.25.233.113" port="5672"
username="test" password="1234" virtual-host="/test" requested-heartbeat="40"/>
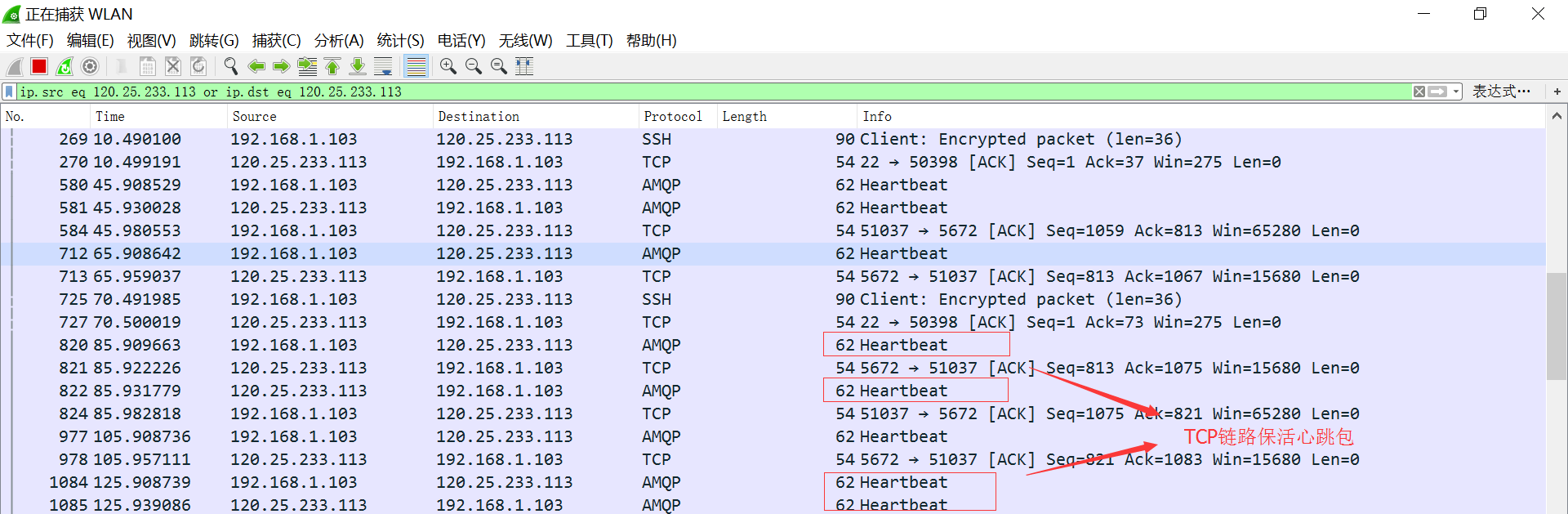
这样就不会出现客户端TCP连接周期性的断开连接问题,后台也就没有这样的错误日志了。